
Optimize Task Allocation via Redundancy in Multi-Agent Systems
Published:
Optimize Task Allocation via Redundancy in Multi-Agent Systems
Summary

Inspiration
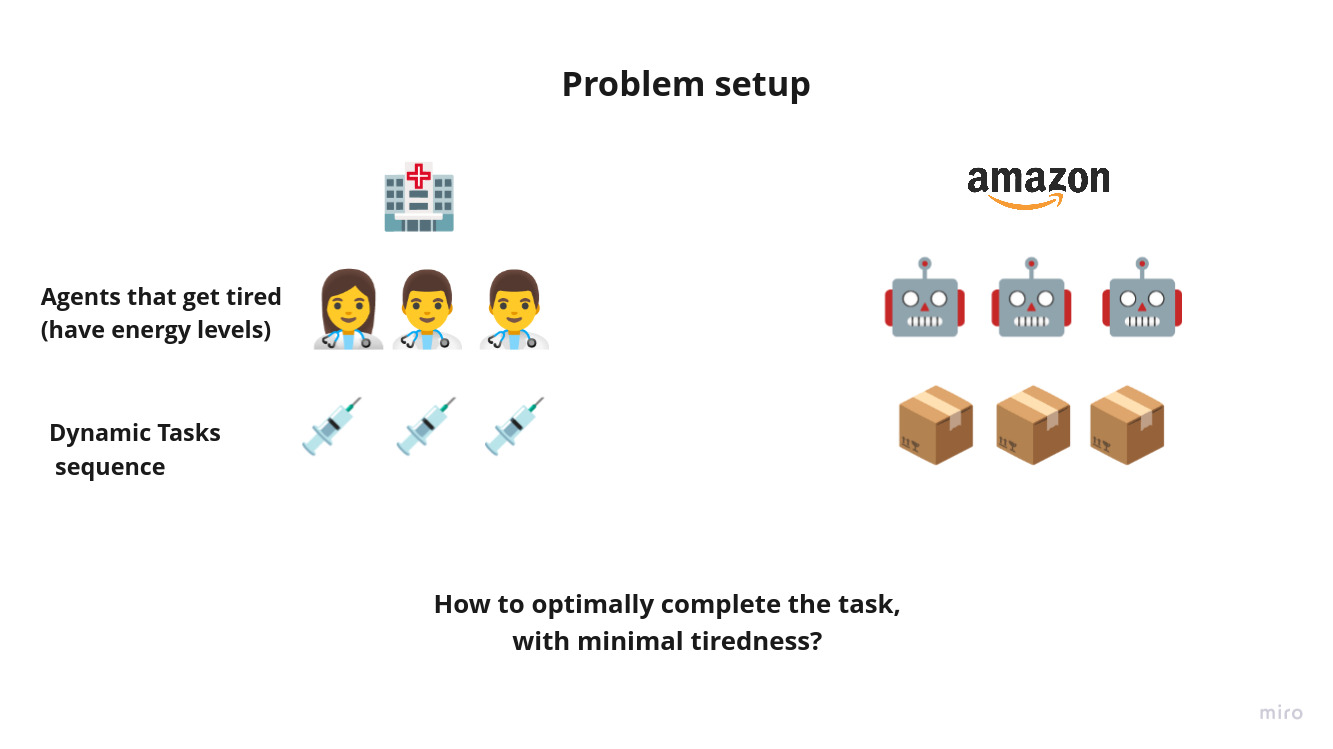
Task allocation is an important problem to be solved. Several real life scenarios require efficient task alloacation, like:
- On-duty Nurses/physicians in patient wards
- Amazon warehouse robots for delivery of objects.
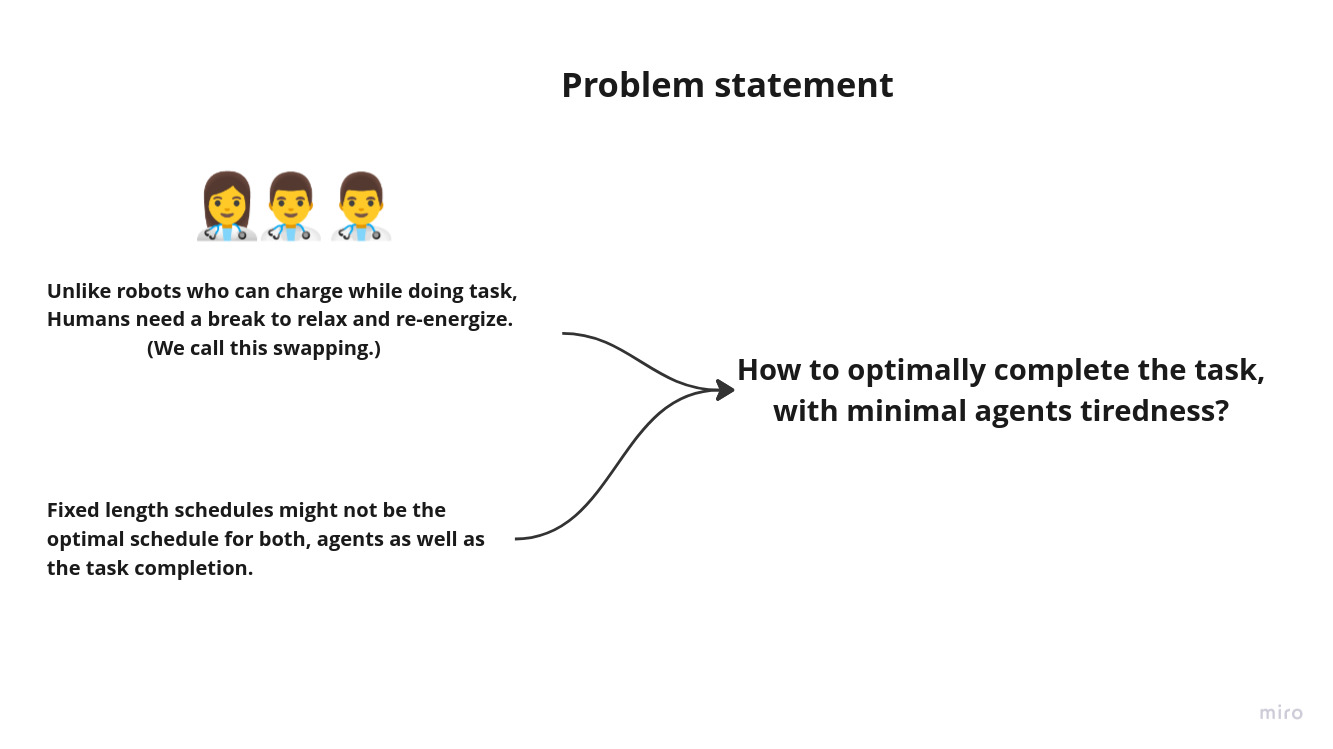
While robots can continously charge as the do tasks, human and other agents require a break to refersh before the start the task again. We explore this problem of extra/redudant agents to take over other agents. Instead of fixed length shifts, we explore impact of giving agents the ability to ask other agents to takeover.
| Context | Problem statement |
|---|---|
 |  |
Experiment setup
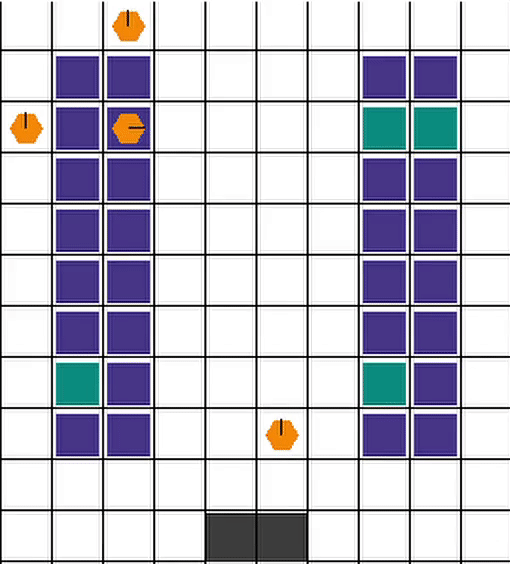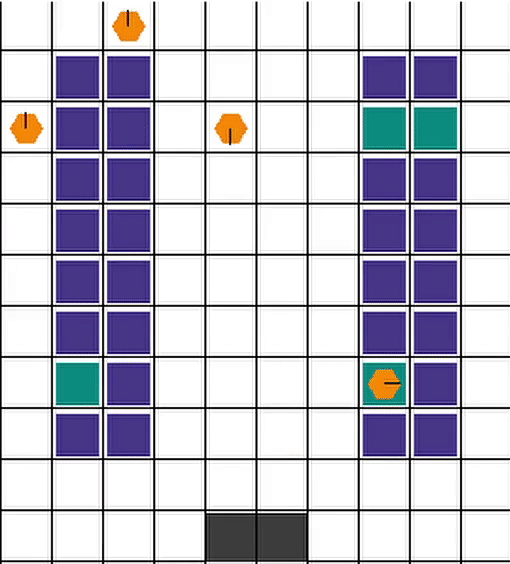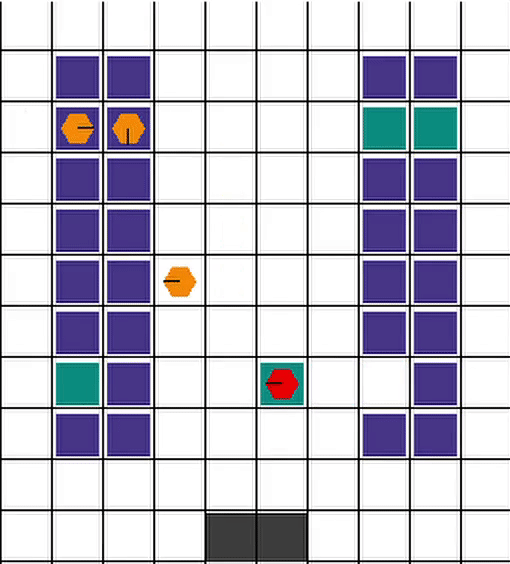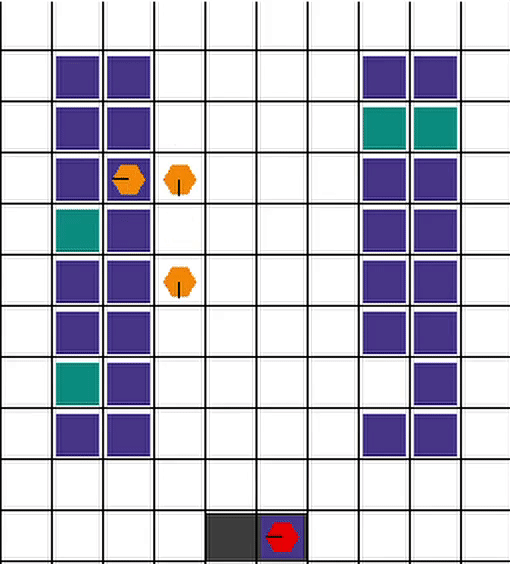
We consider a 4 agent setup, where 3 active agents and 1 inactive agent. We ask the agents to perform the pick and place items task on the goal locations. Each agents has a energy level, which dimishes as it performs the task. On certain threshold(i.e. when agent gets tired), agent can ask inactive agent to takeover. While, having redudant agent might lead to overall in-efficinies, We want to explore the impact of tiredness factor and task distribution between different agents.
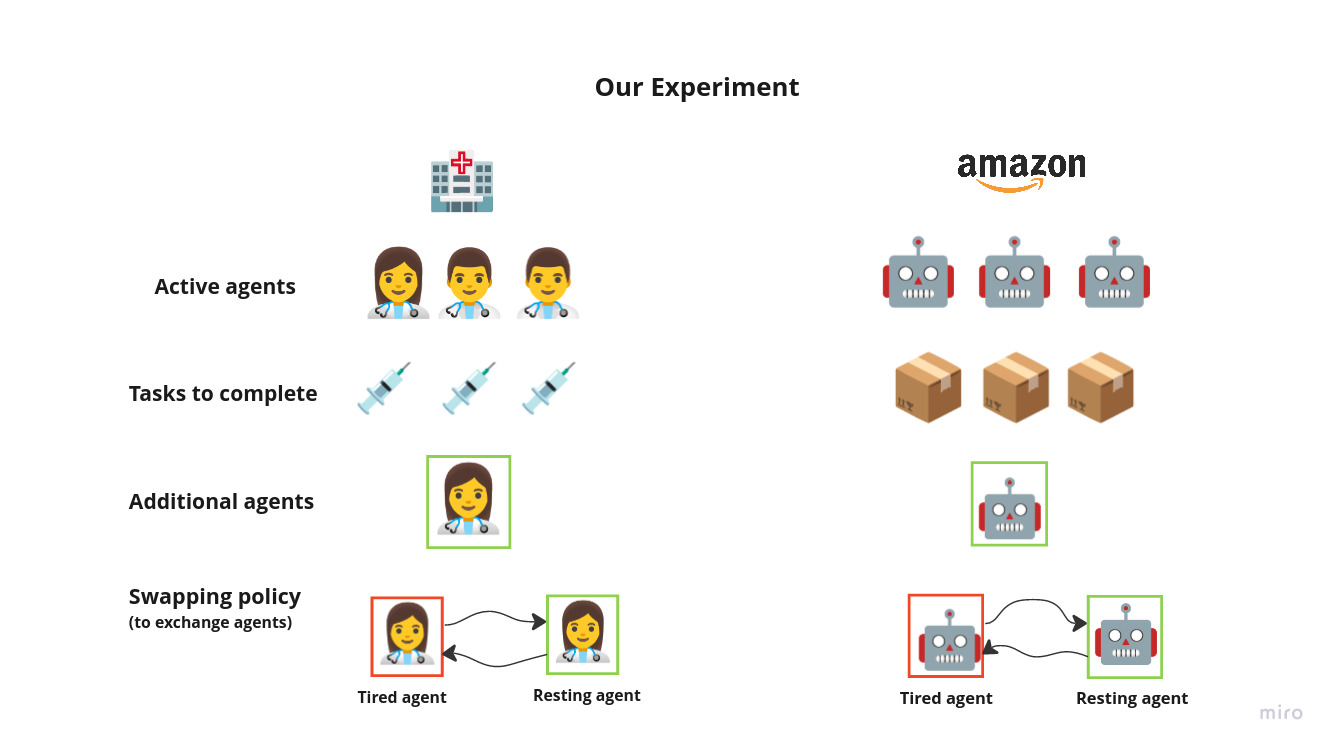
We use RWARE (a multi-robot warehouse) environment, as it already implements the collision aviodance and other warehouse dynamics, and add following properties to this environment/agents:
- Agent Swapping
- Agent energy/charge levels
- Swapping policies
Agent actions -
- LEFT
- RIGHT
- FORWARD
- LOAD/UNLOAD
- SWAP (Conditional)
Reward type -Individual Agent Attributes Energy level - (0 to 200) (Failure occurs at energy level = 0)
Learning task for agents
In order to succeed, agents need to learn the navigation of task, as well as the swap. The swapping behaviour is agent dependent, meaning unless the agent fail(i.e. energy level reaches zero), the agents have to raise a swap for another agent to take over.
Swapping Policies
- Policy 0 - No Swapping
- Policy 1 - Swapping only in case of failures, no Swapping otherwise
- Failure occurs when energy level reaches 0
- Failed agent swaps positions with a charged redundant robot
- Policy 2 - Battery swap/Agent “teleport” to exchange position
- Agent becomes inactive for charging when energy level drops below 25% and requests reallocation
- A charged (energy level >= 60%) inactive agent becomes active
- If no reallocation is requested then the agent becomes active after it reaches 90% charge
- Policy 3 - Remote agent takeover
- Agent becomes inactive for charging when energy level drops below 25% and requests swap
- A charged (energy level >= 60%) inactive agent swaps positions with the inactive agent
- If no swap is requested then the inactive agent becomes active after it reaches 90% charge
Example of swapping: Timestep x-1 => Agent_active = [0,0,1,1] , Agent energy = [180, 190, 30, 100] , agent_2 wants to swap, swapaable agents = 0,1, we swap with agent 1. - Policy 1, Agent_active = [0,0,1,1] , Agent energy = [180, 190, 30, 100] - Policy 2, Agent_active = [0,0,1,1] , Agent energy = [180, 30, 190, 100] - Policy 3, Step x => Agent_active = [0,1,0,1] , Agent energy = [180, 190, 30, 100]
Metrics to measure:
Training
Algorithm used - Proximal Policy Optimization (PPO)
Training progress wtth diff policies till 500K time steps
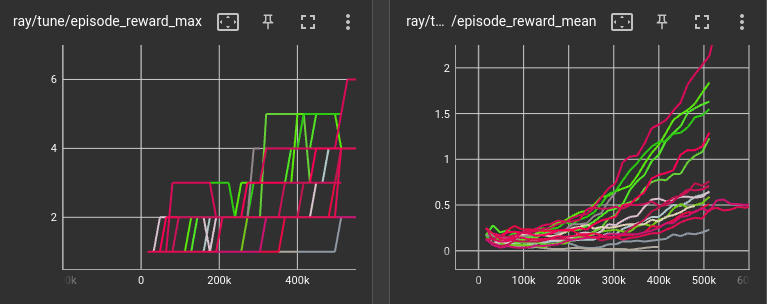
Training progress wtth diff policies till 2 million time steps
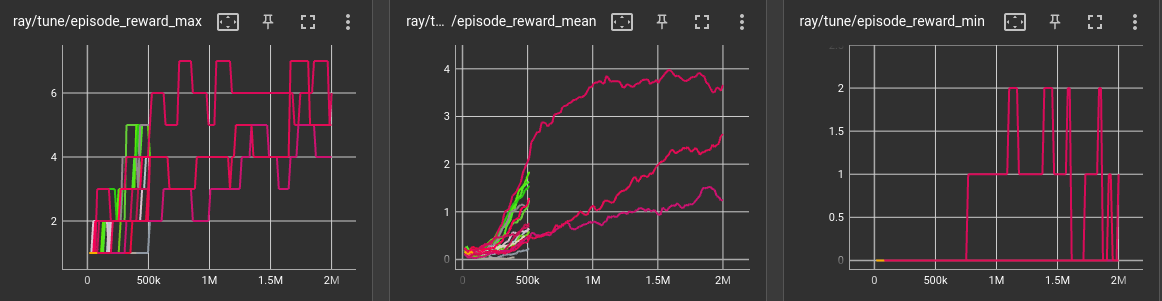
Hyperparamter optimisation

Visual animation
| Random walk | Policy 2 | | :—: | :—: | |  |
|  |
|
Results and Discussion
Comparison of total energy levels for all 3 policies



| Dicharge-Charge ratio | Energy spent on tasks | Energy spent on recharging |
|---|---|---|
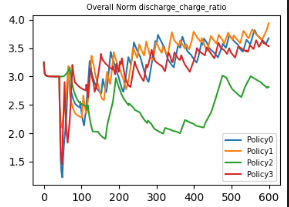 |  | 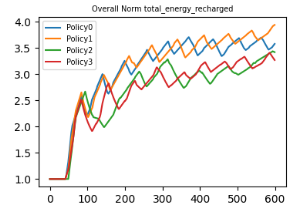 |
During trianing the agents were trained using episode length of 300. We test agents for about twice this length, that is 600 timesteps. As seen from graphs above, policy 2 is most effective in maintaining overall lower discharge/charge ratio, which means that agents spend more time in doing task than charging. Also, Policy 2 has a lower overall charge consumption for doing the task, while maintaing almost similar charge consumption for recharging.
Tasks acheived
- Modify failed agents
- Cap Max active agents
- Add enegry layer to final/ Energy level as part of info : make_obs modify
- Done status of agents
- Train PPO algorithm
Future work/improvments
Try other algorithms Complex reallocation policies Replacement robot traversing to the failed robot Adding charging stations to charge battery Varying the speed of the robots based on the energy level Training replacement robot to swap instead of the failed robot requesting a swap. Adding more properties that would affect the robot efficiency and failure.
Team members
- Amritpal Singh [a]
- Richa Kulkarni [a]
- Shivangi Deo [b]
a. College of Computing, Georgia Institute of Technology, USA b. College of Electrical and Computer engineering, Georgia Institute of Technology, USA
Author 1, 2 and 3 were involved in inital ideation and implementation phase of project. Author 1 performed the training RL agents, metrics design, final analysis and report writing.
Github project link
https://github.gatech.edu/asingh880/warehourse_MRS (Gatech login required, Please reach out to ap4.singh@gmail.com for access to the code base.)