Multiagent agent efficient team coordination in Football using QMIX reinforcement learning algorithm
Published:
Github page - https://github.com/Amritpal-001/gfootball_qmix
Project for CS-7641, MS CS Gatech, USA.
Challenges of RL
Challenges of Multi-agent reinforcement learning On top of the exploration-exploitation dilemma, Multi-agent RL faces another dilemma called the Predictability exploitation dilemma. Maximizing performance requires collecting rewards. As in Dec-POMDP agents cannot explicitly com- municate, coordination requires predictability. At times, this predictability can also require ignoring private information. The dilemma is to choose between the benefit of exploiting private observation vs the cost of predictability.
Aim of this report
This report aims to train a multi-agent reinforcement learning algorithm (QMIX) and compare its performance against the 3 baselines (PPO) algorithms provided. We will train the algorithm to control the action of 2 agents (the goalkeeper will act as per hard-coded rules). The following features will be recorded - • Win rate improvement of QMIX over 3 PPO baselines • Mean reward per episode for QMIX and baseline PPO algorithm against Hardcoded game • Successful passes for QMIX and PPO algorithm • Successful shoots for QMIX and PPO algorithm • Reward shaping to promote certain behavior • Other metrics like - Tiredness, Yellow card for QMIX, and baseline (PPO) algorithm
QMIX algorithm
projects/2002-football-qmix-

QMIX algorithm is an off-policy multi-agent reinforcement learning algorithm, built over the Deep Q networks. QMIX algorithm allows training decentralised policies in a centralized end-to-end fashion.
QMIX consists of agent networks and a mixing network.Each agent network produces Qα. These are combined by mixing networks to produce Qtot by using a complex non-linear way. This allows consistency between centralized and decentralized policies. This is in contrast to VDN (where Qtot is simply the sum of all Qα. The mixing network is required only during training and is removed later. The structure of mixing and agent networks is shown in Fig. 2 This allows QMIX to • learns centralized action-value spaces with factored representation that scales well along with the number of agents. • Allows decentralized policies to easily extract via linear- time individual argmax operations. • QMIX can represent a much richer class of action-value functions than VDN. [1]
Final agent results

Training progress of agents
Screenshots
| left_totaltired_min | num_success_pass_mean | score_reward_episode_mean | shoot_attempts_mean | | :—: | :—: | :—: | :—: | | 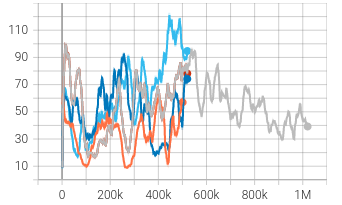 |
| 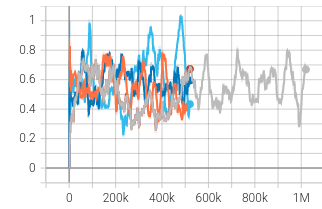 |
| 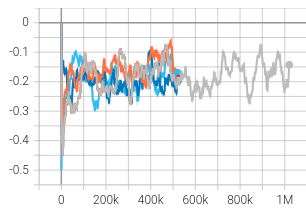 |
| 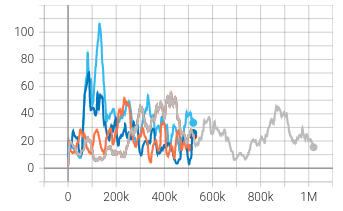 |
|
| win_percentage_episode_mean | left_totaltired_min |
|---|---|
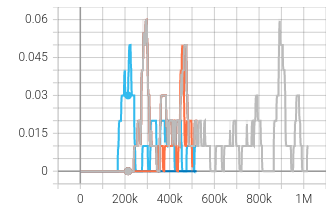 | 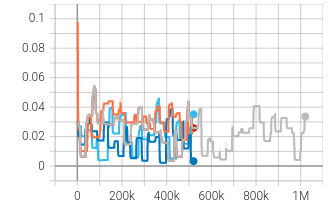 |
Ablation studies
Ablation study to look at effect of using Double Q network. | episode_reward_mean_Blue_DoubleQ | Win_Rate_Blue_DoubleQ | | :—: | :—: |
| 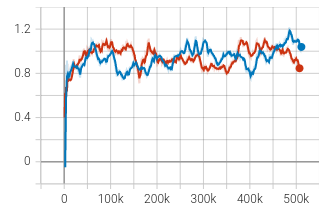 |
| 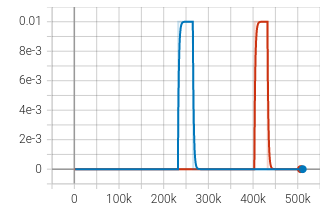 |
|
Initial behaviours learn
Learns to pass, but not always
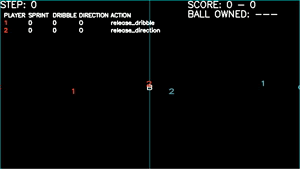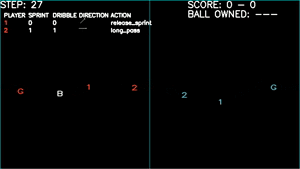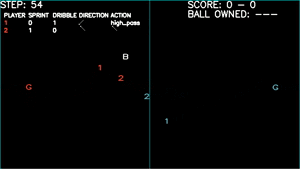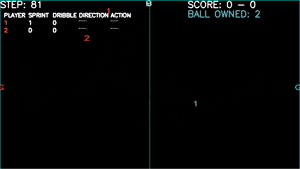
Learns to pass, but uses this to avoid opponent
Weird behaviours learn
Agent learns to get possitive checkpoint reward, as it anyways cant prevent the goal from happening.
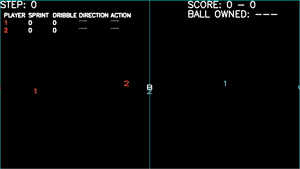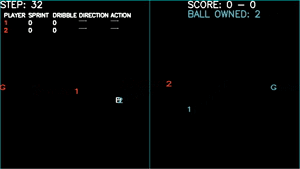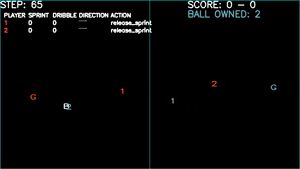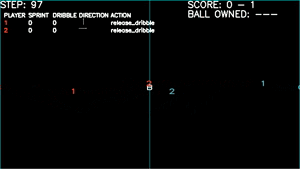
Game plays - Games won
Lets take ball all the way till end
fight_the_goalkeeper
One of the lamest win
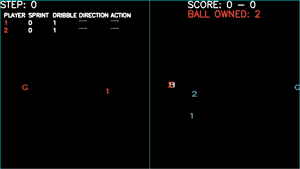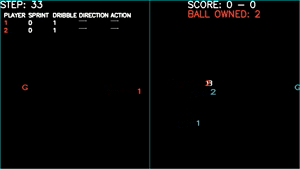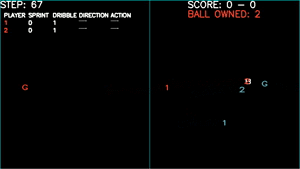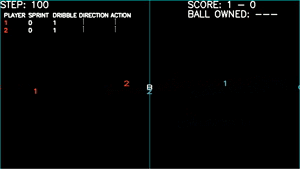
Let literally do it together “As a team”
Shoot to goal
Lost games
Lamest goal - passing turns into goal